Argonne National Labs Bring oneAPI to NWChemEx Project
24 October 2024
Overview
Tailored for pre-exascale and exascale computing environments, the NWChemEx project represents a significant evolution and enhancement of the original NWChem application. NWChem itself is an open-source computational chemistry code, renowned for its high and parallel processing capabilities, originally supported by the DOE Biological and Environmental Research (BER) program. This platform offers extensive functionality for modeling molecular systems.
NWChemEx aims to extend these capabilities further, ensuring compatibility across a spectrum of computing systems—from terascale workstations and petascale servers to cutting-edge exascale machines. Specifically, the project is focused on optimizing and scaling three primary physical models: Hartree-Fock (HF) methods, density functional theory (DFT) methods, coupled cluster (CC) methods, and density functional embedding theory. These enhancements are crucial for advancing chemistry research supported by DOE BER and DOE Basic Energy Sciences.
Scaling to Exascale: Portability & Performance
The NWChemEx Project faces challenges in maintaining a sustainable and portable software ecosystem, particularly with multiple accelerator backends. Currently, we utilize CUDA, HIP, and SYCL to support Nvidia, AMD, and Intel GPUs respectively. However, this approach raises concerns about developer productivity, potential for bugs, and performance benchmarking consistency across different backends.
To address these challenges, our team initially focused on porting existing CUDA kernels to SYCL using SYCLomatic (previously known as Intel DPC++ Compatibility Tool). This effort aimed to streamline development and ensure compatibility across diverse GPU architectures. Collaborating closely with Codeplay, NERSC, Oak Ridge Leadership Computing Facility, and Argonne Leadership Computing Facility, we have successfully developed a cross-platform and portable SYCL implementations for the coupled cluster with single and double (CCSD) excitations, augmented by a non-iterative, perturbative treatment of triple excitations, or CCSD(T), which is considered a gold standard in electronic structure theory.
This collaborative effort is crucial for enhancing the sustainability and efficiency of NWChemEx, ensuring robust support across various accelerator platforms while upholding high standards of performance and reliability. However, managing both HIP and SYCL backends for Aurora at ALCF, equipped with Intel Data Center GPU Max 1550 series GPUs, and Frontier at OLCF, featuring AMD Instinct MI250X GPUs, presents significant challenges.
Moreover, maintaining the traditional CUDA backend, which serves as the test and development programming model for these GPUs due to its widespread availability of hardware and software, before refactoring HIP and SYCL backends, has proven labor-intensive and prone to bugs. This approach has notably hampered our productivity.
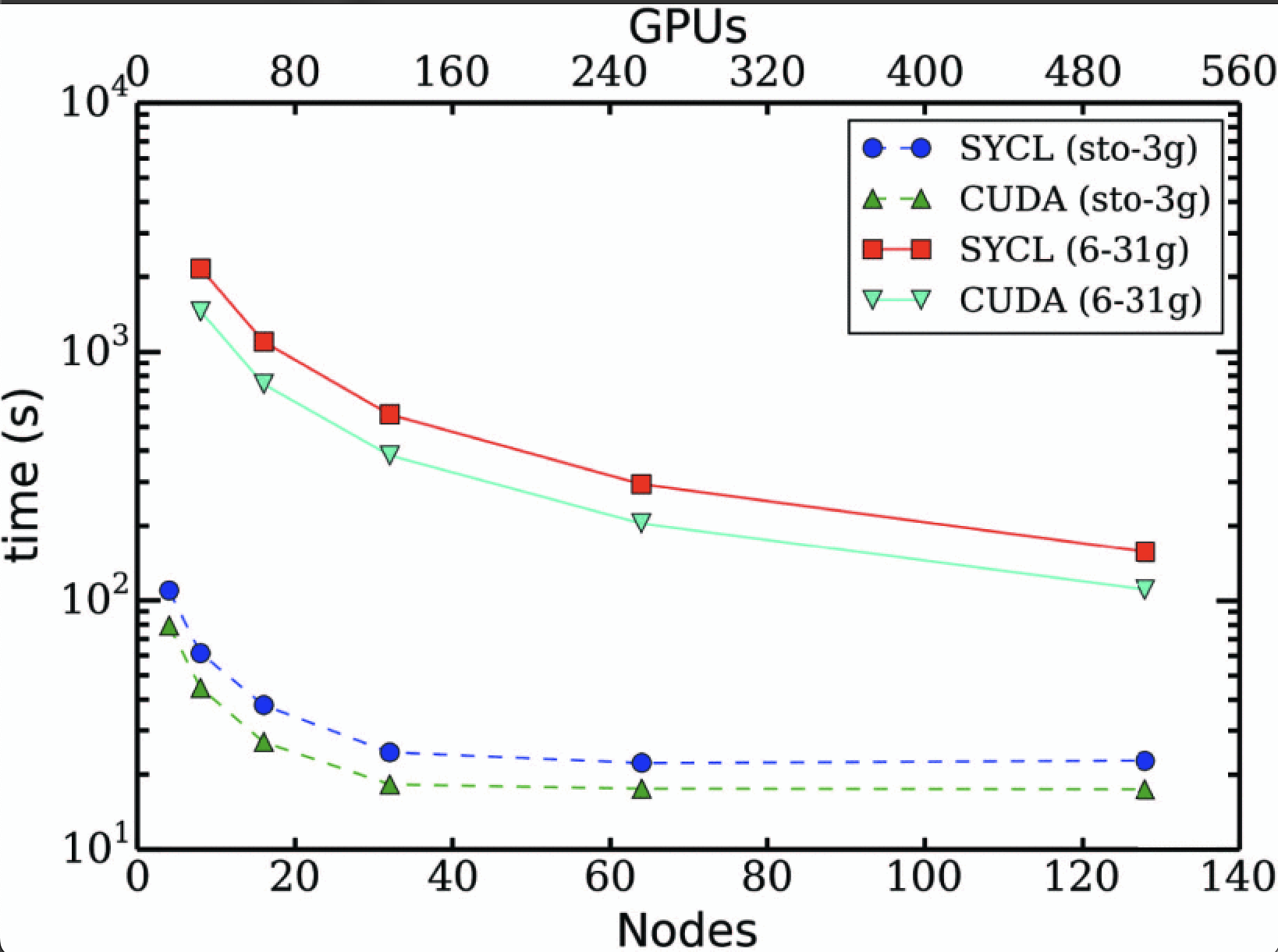
Bagusetty, A., Panyala, A., Brown, G. and Kirk, J., 2022, November. Towards cross-platform portability of coupled-cluster methods with perturbative triples using sycl. In 2022 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC) (pp. 81-88). IEEE
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
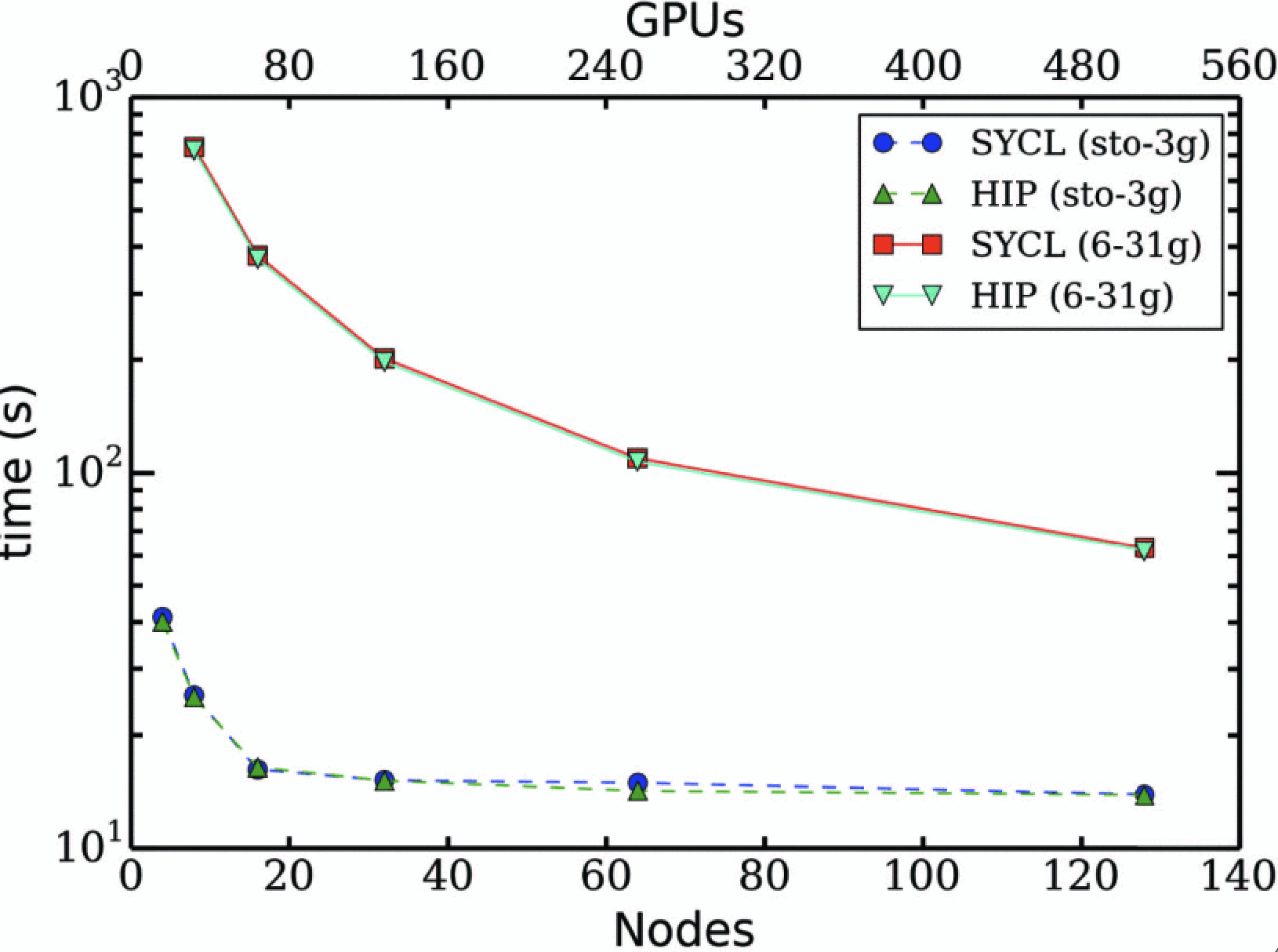
Bagusetty, A., Panyala, A., Brown, G. and Kirk, J., 2022, November. Towards cross-platform portability of coupled-cluster methods with perturbative triples using sycl. In 2022 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC) (pp. 81-88). IEEE
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Challenges & Lessons Learnt
Our case study will now review some of the challenges and lessons learned through our work with oneAPI and the NWChemEx project. Firstly, we will address the challenge with CUDA’s constant memory, before diving into some of the lessons we’ve learned with performance portable libraries, hardware choice with heterogeneous code and the impact on debugging. Hopefully this retrospective will be useful if you are considering your own implementation of SYCL or oneAPI.
Case of CUDA’s constant memory: During our transition from CUDA to SYCL, we encountered a challenge involving how to manage the usage of CUDA's constant memory data structures in SYCL. The SYCL specification does not support a direct equivalent, leaving us to explore alternative approaches in our code structure. We leveraged two SYCL extensions: sycl_ext_oneapi_device_global and sycl_ext_oneapi_usm_device_read_only, along with specialization constants. Our approach involved mapping CUDA's constant memory to SYCL's sycl_ext_oneapi_usm_device_read_only, which effectively provided the required functionality with minimal code refactoring.
Story of Performance Portable Libraries: Quantum chemistry methods heavily rely on tensor contractions, particularly in calculations involving single and double excitations within the CCSD formalism. These contractions are often implemented using General Matrix Multiply (GEMM) routines, which are crucial for computational efficiency.
To optimize these operations on GPUs, we utilize highly optimized math libraries provided by GPU vendors such as cuBLAS, rocBLAS, and the oneMKL APIs for Level 3 GEMM routines. The oneMKL interfaces, originally designed for Intel GPUs, have been extended to support Nvidia and AMD GPUs as well. These APIs serve as lightweight wrappers for the underlying vendor-specific accelerated math libraries (e.g., cuBLAS, rocBLAS), ensuring minimal latency and enabling performance portability across different GPU architectures.
Furthermore, the oneMKL specification falls under the governance of the UXL (Unified Acceleration Foundation), which aims to unify the heterogeneous compute ecosystem around open standards. This standardization helps streamline development and deployment across diverse hardware platforms, enhancing overall computational efficiency in quantum chemistry simulations.
No hardware left behind: SYCL is a Khronos standard that enables fully heterogeneous data parallelism in ISO C++. By adopting the single-source paradigm for heterogeneous architectures, it facilitates concurrent utilization of CPUs, GPUs, FPGAs, and other devices. SYCL for CPUs serves as a proxy for developing and debugging code refactoring aimed at GPU backends, especially when direct GPU hardware access is restricted.
For CPU execution, SYCL is supported through the oneAPI Construction Kit (OCK) by Codeplay. Additionally, the portability of oneMKL interfaces allows projects to execute on CPUs using open-source libraries such as netlib, portBLAS, and portFFT. This setup provides a robust environment for testing and developing end-to-end frameworks.
We have been exploring the utilization of Nvidia Tensor Cores, AMD Matrix Cores, and Intel Xᵉ Matrix Extensions (Intel® XMX) on compatible hardware, leveraging supported data-type precisions. Programming for these specialized hardware units has traditionally involved using vendor-specific APIs and assembly language instructions, which can be cumbersome. However, with the introduction of DPC++'s SYCL joint matrix extension, programming for these hardware components has become significantly easier and ensures performance portability.
Portable tools for debugging and profiling: In leveraging SYCL for various GPU backends within NWChemEx, the integration of debuggers and profilers becomes crucial. With the maturation of the DPC++ implementation of the SYCL specification over time, we have been able to effectively utilize debuggers such as cuda-gdb and ROCgdb to debug sections of our SYCL code running on Nvidia and AMD platforms. Similarly, profiling tools like Nvidia Nsight Compute and ROC profiler have provided us with detailed insights into performance characteristics.
This approach grants us significant control over SYCL as a portable programming model without sacrificing productivity. The availability of a wide array of tools and robust SYCL compilers ensures that our code development process remains comparable to using vendor-specific GPU programming APIs.
Khronos® is a registered trademark, and SYCL™ is a trademark owned by The Khronos Group Inc. All other product names, trademarks, and/or company names are used solely for identification and belong to their respective owners.
